
در این مقاله تعریف خوشه بندی و مراحل انجام فصل 4 پایان نامه با خوشه بندی معرفی می گردد.
مفهوم خوشه بندی
خوشه بندی به روشي گفته مي شود كه با استفاده از آن مي توان داده هاي نمونه را به چند خوشه يا طبقه، رده بندي كرد به طوري كه داده هاي قرار گرفته شده در هر خوشه، همگون و يكسان باشند و بين خوشه ها بيشترين تفاوت و ناهمگونی وجود داشته باشد. البته این گونه خوشه بندی زمانی صورت می گیرد که پراکندگی جامعه ای که نمونه از آن گرفته شده، زیاد باشد. در این حال، شرط اساسی برای تشکیل خوشه ها این است که خوشه ها افرازی از جامعه یا نمونه باشند. یعنی هر داده تنها در یک خوشه قرار گیرد و از طرفی اجتماع تمام خوشه ها، برابر کل نمونه یا جامعه مورد نظر باشد.
مثال خوشه بندی
خوشه بندی تقریباً در هر جنبه از زندگی روزمره اتفاق می افتد. کنار هم قرار دادن انواع گوشت و سبزیجات در محل های یکسان و نزدیک به هم، نوعی خوشه بندی در سوپر مارکت ها است. کنار هم قراردادن گونه های مختلف حیوانات توسط زیست شناسان بر اساس ویژگی های مشترکشان مثال دیگری برای خوشه بندی است.
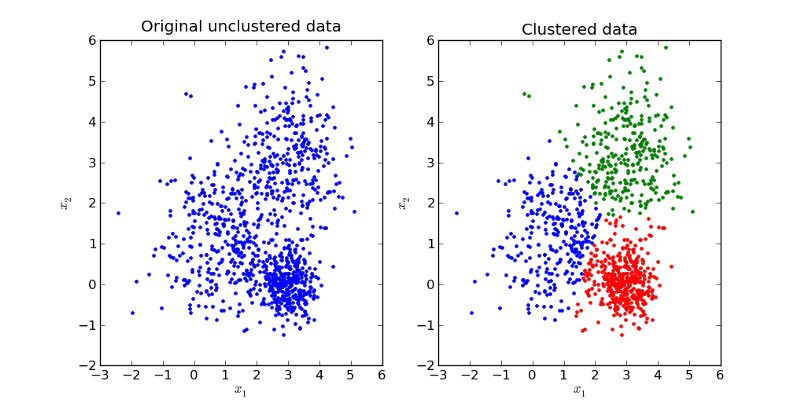
داده های خوشه بندی شده در مقابل داده های بدون خوشه بندی
انواع مختلف الگوریتم های خوشه بندی
انواع مختلفی از خوشه بندی وجود دارد که در این مقاله به مرور کلی برجسته ترین آن ها پرداخته می شود. احتمالا بیش از 100 الگوریتم خوشه بندی منتشر شده وجود دارد که ابداع کنندگان آن همه مدل ها برای روش خود را ارائه نمی دهند و بنابراین نمی توانند به راحتی دسته بندی شوند.
خوشه بندی مبتنی بر توزیع
بر اساس این روش، داده ها بر اساس احتمال به نزدیک ترین توزیعی که ممکن است به آن تعلق داشته باشند خوشه بندی می شوند. گروه بندی داده ها ممکن است از نوع نرمال و یا گاوسی باشد.
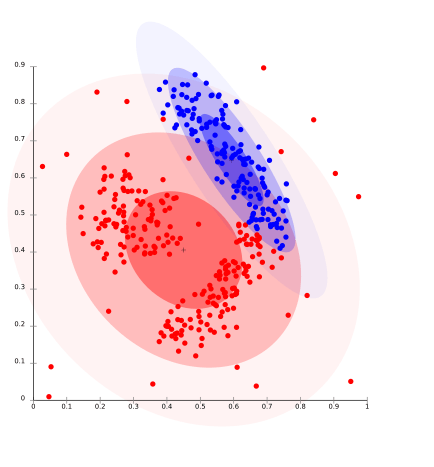
این روش برای داده های آمیخته و خوشه های با اندازه متفاوت به خوبی عمل می کند. اما در صورتی که این قیود برای محدود کردن پیچیدگی مدل استفاده نشود، ممکن است این روش مشکل داشته باشد. علاوه بر این، خوشه بندی مبتنی بر توزیع، خوشه هایی را تولید می کند که بر اساس آن مدل های ریاضی تعریف شده بر اساس داده ها، فرض قوی برای اثبات توزیع داده ها است. الگوریتم EM که از توزیع نرمال چندمتغیره استفاده می کند محبوبت ترین این روش می باشد.
خوشه بندی مبتنی بر مرکز ثقل
روش خوشه بندی مبتنی بر مرکز ثقل یکی از روش های ابتدایی است که خوشه ها بر اساس نزدیکی داده ها به نقاط مرکز ثقل هر خوشه تشکیل می شوند. به طوری که مرکز خوشه ها به نوعی تعیین می شوند که فاصله داده ها با آن نقطه حداقل باشد. برای مثال الگوریتم K-میانگین یکی از روش های محبوب این نوع خوشه بندی است.
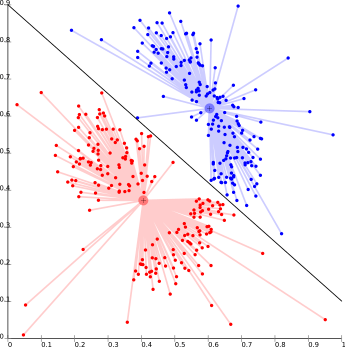
بزرگترین مشکل این الگوریتم این است که باید تعداد خوشه ها (K) را از قبل مشخص نماییم. این مسئله در توزیع خوشه ای مبتنی بر توزیع داده ها نیز وجود دارد.
خوشه بندی مبتنی بر اتصال
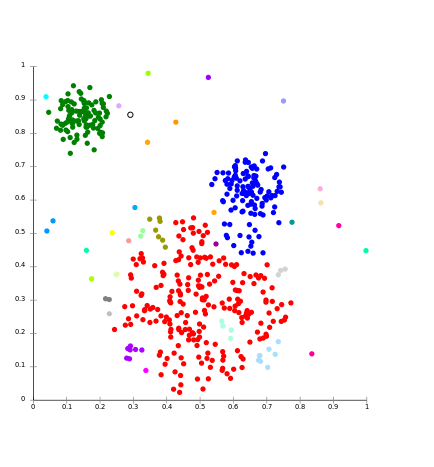
ایده اصلی خوشه بندی مبتنی بر اتصال مشابه به مدل مبتنی بر مرکز ثقل است که اساسا خوشه ها را بر اساس نزدیک بودن نقاط داده تعیین می کند. این روش خوشه بندی بر روی یک مفهوم کار می کند که نقاط داده هایی که نزدیک هم هستند رفتار مشابهی نسبت به داده های دورتر دارند. این روش یک جداسازی واحد از مجموعه داده ها نیست، بلکه یک سلسله مراتب گسترده ای از خوشه ها که در فواصل خاص ادغام می شوند، فراهم می کند. در این روش انتخاب تابع فاصله ذهنی است. این مدل ها برای تفسیر بسیار آسان هستند، اما فاقد مقیاس پذیری می باشند. خوشه بندی سلسه مراتبی و انواع آن مثالی برای این روش است. منبع
انجام فصل 4 پایان نامه با خوشه بندی k-Means
برای انجام فصل 4 پایان نامه با خوشه بندی روش های مختلفی وچود دارد. خوشه بندی k میانگین، کاربردی ترین روش خوشه بندی داده ها است. این روش اولین بار توسط مک کویین در سال 1967 ارایه شد. تعداد خوشه ها در این روش ثابت و از پیش تعیین شده است این روش برای خوشه بندی داده هایی طراحی شد که به صورت عددی (کمی) باشند و خوشه دارای مرکزی به نام «میانگین» باشد. در این روش، ابتدا اشیاء به صورت تصادفی به k خوشه تقسیم می شوند. در گام بعد، فاصله هر یک از اشیاء از مرکز خوشه خود محاسبه میشود. در صورتی که فاصله شی مورد نظر از میانگین خوشه خود زیاد و به خوشه دیگری نزدیکتر باشد، این شی به خوشه ای که نزدیکتر است اختصاص می یابد. این کار آنقدر تکرار میشود تا تابع خطا حداقل شود، و یا اعضای خوشه ها تغییر نیابد.
برای انجام فصل 4 پایان نامه با روش خوشه بندی k-Means باید موارد زیر مد نظر قرار گیرد :
- خوشه بندی کا-میانگین برای نمونه های با حجم بالا استفاده می شود.
- در خوشه بندی K-میانگین، با توجه به هدف پژوهش می توان هم پاسخ گویان و هم متغیرها را خوشه بندی کرد.
- سطح سنجش متغیرها در خوشه بندی k-Means، فاصله ای و اسمی و دو وجهی می باشد.
- بایستی فرضیاتی درباره تعداد خوشه ها در اختیارتان موجود باشد.
یکی از معیارهایی که به انتخاب مناسب تعداد خوشه ها کمک می کند شاخص دیویس بولدین است. بدین صورت که این شاخص برای بهترین k، کمترین مقدار خود را اختیار می کند.
در این راستا موسسه آماری کوکرانا آماده انجام فصل 4 پایان نامه با روش خوشه بندی k-Means بسته به نوع روش تحقیق با استفاده از نرم افزارهای (… ,Rapidminer, Matlab ,SPSS, Clementine) برای متقاضیان گرامی می باشد.
نگارش فصل 4 پایان نامه با خوشه بندی سلسه مراتبی
خوشه بندی سلسله مراتبی تکنیکی است که در خوشه بندی داده ها به کار می رود. نقاط داده ها در این روش در دسته ها و زیر دسته هایی بر اساس معیار شباهت قرار می گیرند. در روش خوشه بندی سلسله مراتبی، به خوشه های نهایی بر اساس میزان عمومیت آن ها ساختار سلسله مراتبی، معمولا به صورت درختی نسبت داده می شود. به این درخت سلسله مراتبی دندروگرام می گویند. برای انجام فصل 4 پایان نامه با خوشه بندی سلسه مراتبی بایستی به موارد زیر توجه داشت :
- تحلیل خوشه ای سلسله مراتبی نسبت به سایر روش ها، بیشتر استفاده می شود.
- تحلیل خوشه سلسله مراتبی برای نمونه های زیر هزار نفر نیز استفاده می شود.
- در این تحلیل، با توجه به هدف پژوهش می توان هم پاسخ گویان و هم متغیرها را گروه بندی یا خوشه بندی کرد.
- سطح سنجش متغیرها در تحلیل خوشه ای سلسله مراتبی، فاصله ای و اسمی دووجهی می باشد.
این روش دارای یک ساختار درختی است که در هر مرحله با جداسازی پاسخ گویانی که شبیه هم می باشند آغاز شده و در مرحله بعد با ادغام آنها در یک خوشه یا درخت، ترسیم می شود.

دیدگاه خود را بنویسید